Le Trameur et les nuages
On va traiter nos corpus qui sont obtenus en suivant les instructions de l’épisode dernier avec le logiciel leTrameur et on va faire les nuages de mots pour chaque langue.
Comme j’ai eu des problèmes à ouvrir leTrameur sur mon ordinateur, M.Fleury m’as conseillé d’utiliser iTrameur (leTrameur en ligne) pour analyser nos résultats;
iTrameur – « Nuage-JS » permet de construire un nuage de mots : http://www.tal.univ-paris3.fr/plurital/outils/wordcloudjs/index.html
- iTrameur – « CooCs-JS » permet de construit de construire un graphe de cooccurrents sur un pôle donné: http://www.tal.univ-paris3.fr/plurital/outils/coocjs/index.html
- iTrameur – « CooCs-JS-regexp » permet de construire un graphe de cooccurrents sur un pôle donné (via une regexp) : http://plurital.org/outils/coocgen/index-regexp.html
- iTrameur – « Réseau CooCs-JS » permet de construire un réseau de cooccurrences généralisées : http://www.tal.univ-paris3.fr/plurital/outils/coocgen/index.html
Pour le chinois, j’utilise iTrameur cooCs-JS en donnant un pôle « 边境 » ( frontières) et avec un seuil de 7, voici le graphe de coocurrence:
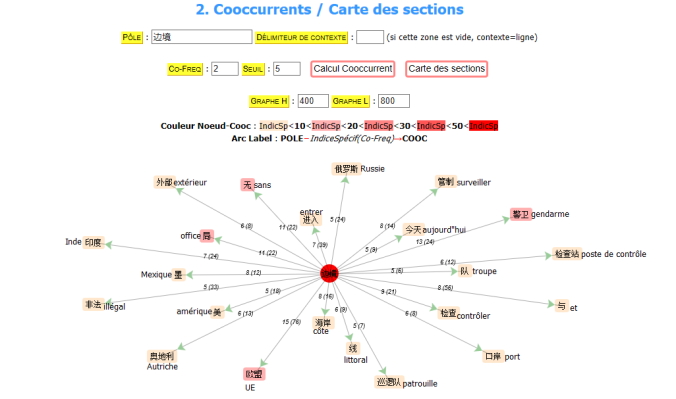
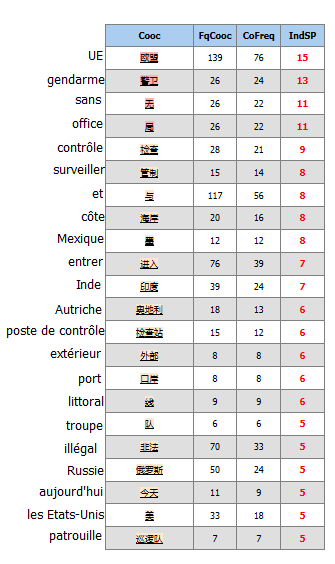
Pour faire comprendre tout le monde, je traduit tous les mots chinois en français.
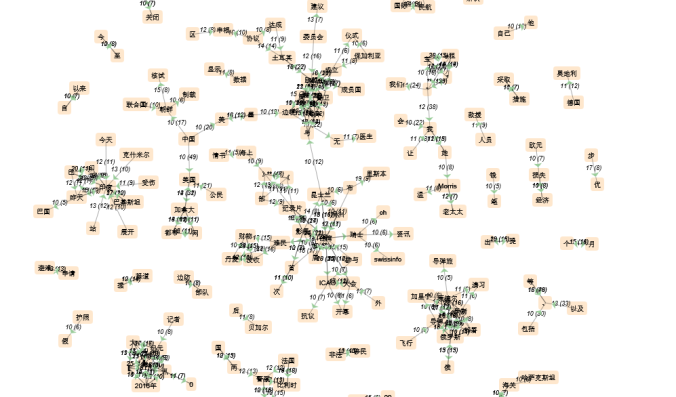
et aussi; pour impliciter les relations entre les mots; j’ai utilisé iTrameur – « Réseau CooCs-JS » qui permet de construire un réseau de cooccurrences généralisées.
je remets le seuil en 10; sinon, le graphe va être comme une pelote et on voit rien. voici une partie de notre graphe de réseaux; il est beaucoup plus compliqué que celui de coocurances et on ne peut pas tout traduire, mais j’ai essayé de le lire et de l’analyser; ça m’as donné des informations intéressantes:
En ce qui concerne le nuage; j’ai fait deux nuages de mots à l’aide de Word Cloud Generator pour le chinois; l’un de CONTEXTE:

l’autre de DUMP-TEXT:

****Italien****
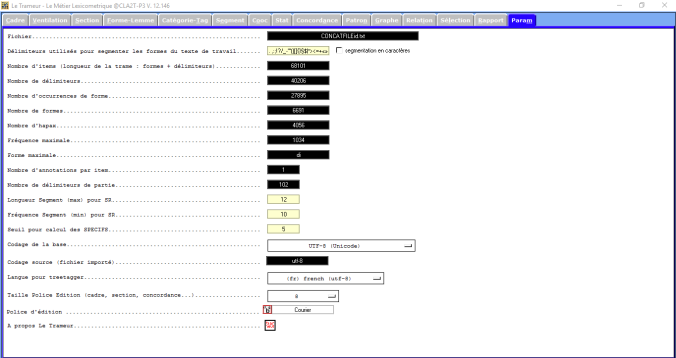
Pour ce qui concerne l’italien, on peut très bien utiliser Le Trameur pour faire notre analyse. Dés que l’on charge notre fichier concatené, voilà apparaître les paramètres de notre CONCATFILE.txt. Ici, on peut trouver des informations utiles sur notre fichier (encodage, etc).
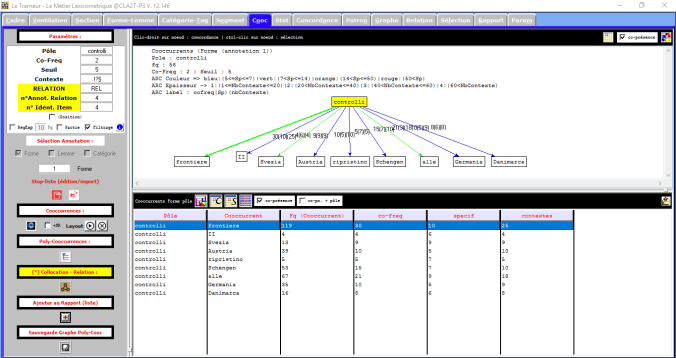
On se deplace maintenant sur l’onglet Cooc pour effectuer l’analyse de notre corpus. Dans la case « Pole » on écrit le mot dont l’on veut calculer la fréquence et lest mots qui apparaissent les plus souvent dans le même contexte du mot choisi. Prenons le mot « frontiere » sur lequel on travaille et on choisi un seuil de 5.
Voilà le résultat!
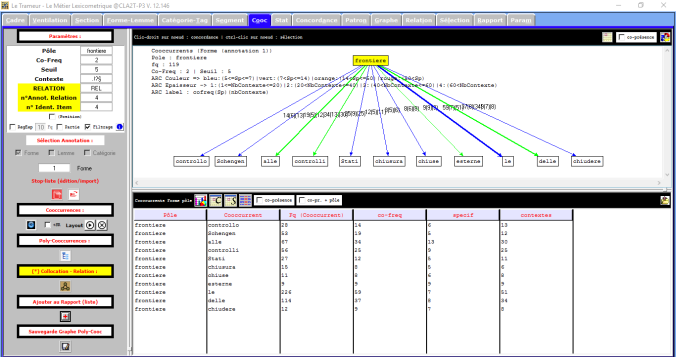
On peut remarquer que le mot « frontiere » apparaît souvent avec les mots « controlli » (contrôles ), »controllo » (contrôle) et « Schengen ». De suite, la photo d’une partie de la liste du mot « Schengen » dans ses différents contextes.
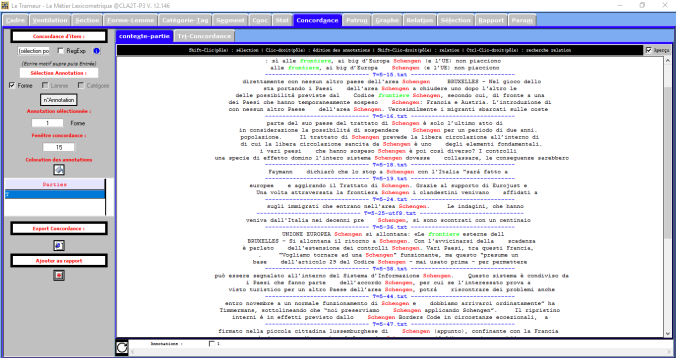
De plus, on voit apparaître trois mots qui ont le même sens mais qui sont exprimés différemment , par example « chiusura » (fermeture), « chiuse » (fermées) et « chiudere » (fermer). On va essayer maintenant de répéter l’analyse avec un seuil de 7. On voit clairement que le nombre de Cooccurents diminue.
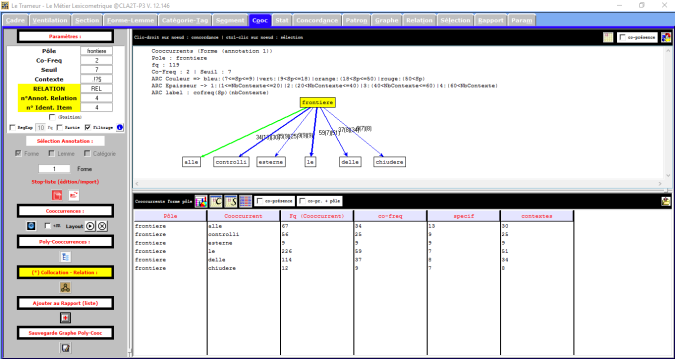
Les analyses effectuées jusqu’à là ne concernent que le mot « frontiere » (pluriel) et si l’on cherchait aussi le mot « frontiera » (singulier)?
Voilà le résultat de la recherche avec un seuil de 5.
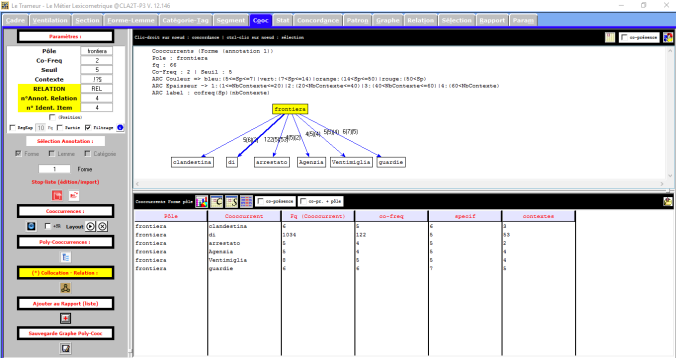
On remarqué que le résultat du mot au singulier n’est pas le même que celui du mot au pluriel; « frontiera » est utilisé surtout avec « clandestina » (clandestine), « Ventimiglia » (Ventimille) et « guardie »(gardes, agents).
Après avoir utilisé Le Trameur, il ne nous reste qu’un dernier passage: la nuage de mots, crée avec Tagul sur le site suivant https://tagul.com. On a choisi ce site puisqu’il nous permet d’effacer certains mots que l’on ne veut pas prendre en considération pour notre nuage, comme par exemple les prépositions. Voilà la nuage de mots sur le fichier DUMP-TEXT:

Et celle sur le CONTEXTE:

***Français***
On va maintenant analyser la langue française.
Comme pour la langue italienne, on peut remarquer que le mot « frontières » apparaît la plupart de fois avec les mots « contrôles », « contrôle » et « Schengen ».
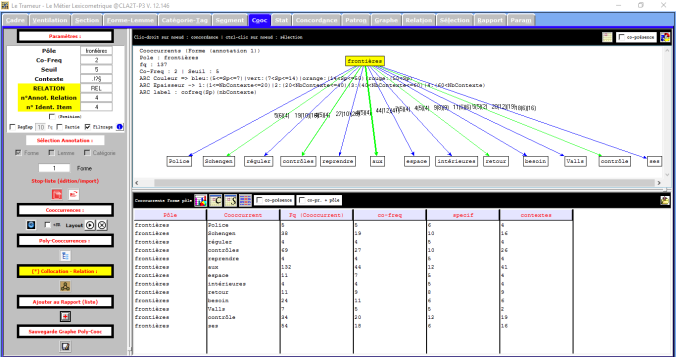
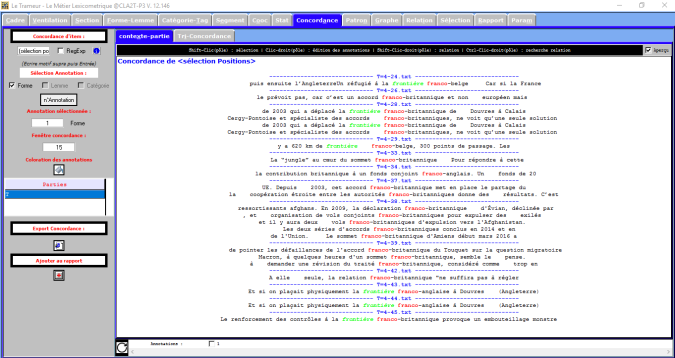
Si l’on cherche le mot « frontière » il y a un changement par rapport aux résultats: ce mot au singulier est utilisé souvent avec les mots »franco », « britannique », « belge », « anglaise », etc. et bien aussi avec le mot « calais » qui fait référence au problème des immigrants qui voulaient aller au Royaume-uni.
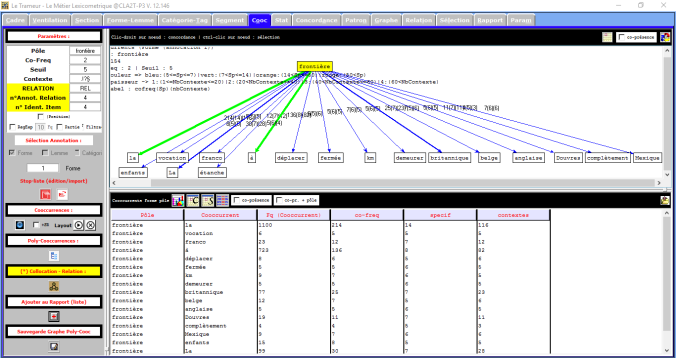
Voilà par exemple le mot « franco » dans son contexte:
Voilà la nuage de mots sur le fichier DUMP-TEXT:

Et celle sur le CONTEXTE:

***Arabe***
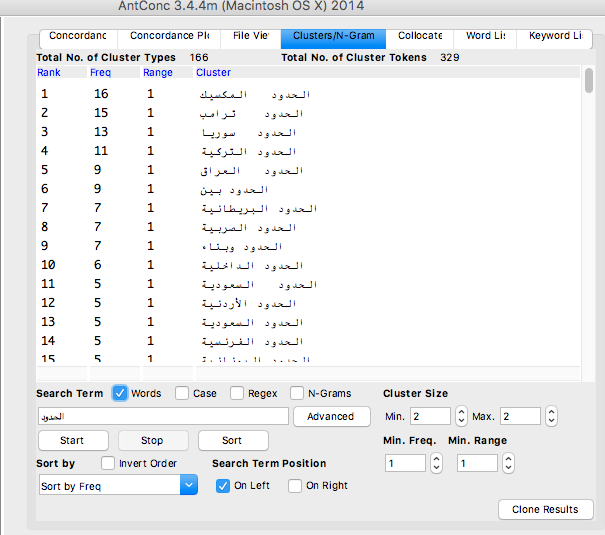
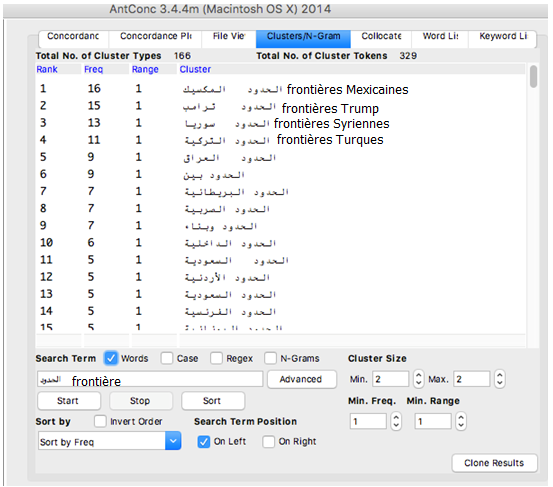
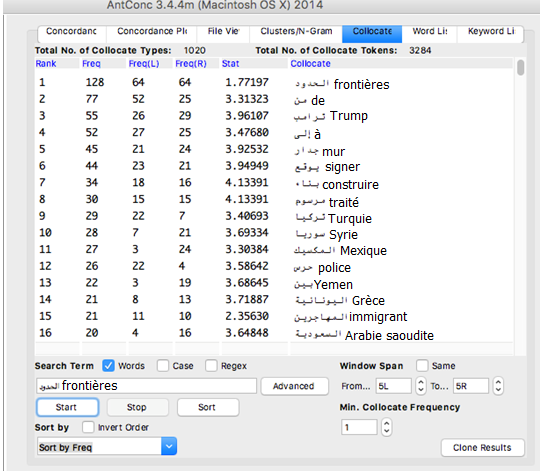
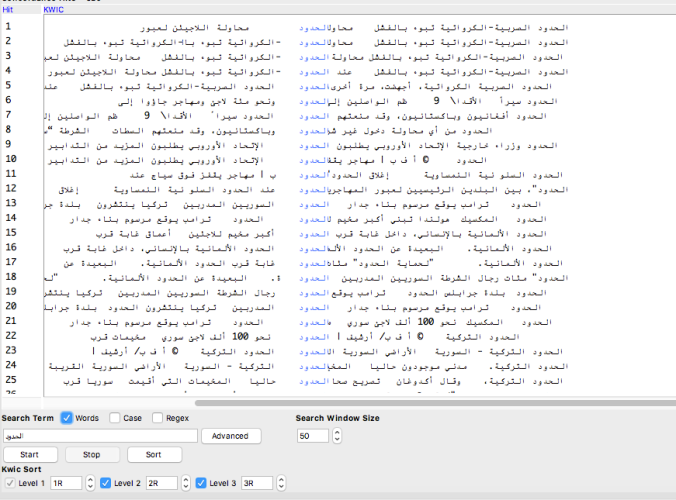
Analyse : Pour le mot frontières en arabe, on trouve souvent que ce mot est toujours suivie par le mot syrienne ou turque. on remarque aussi que le mot frontières est souvent apparu dans le contexte ou on trouve les présidents Erdogan et Trump. Ainsi lorsqu’on parle d’états-unis on remarque l’apparition du mot « mur », mais quand on parle de mot frontières dans le monde arabe, le mot « fuir » prend la place.
***Anglais***
On va maintenant analyser le mot « borders » la langue anglaise.
On remarque que si l’on choisi un soeuil de 5 on va avoir trop de coocurrents.
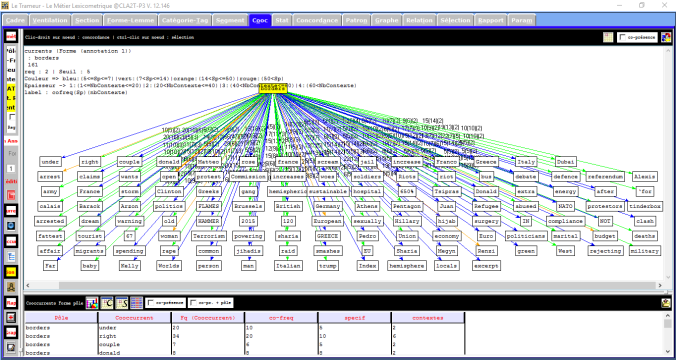
On va alors changer le soeuil de 5 à 13 et voilà un résultat plus facile à analyser.
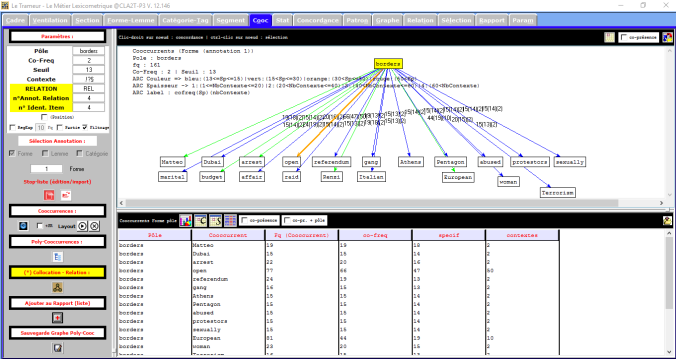
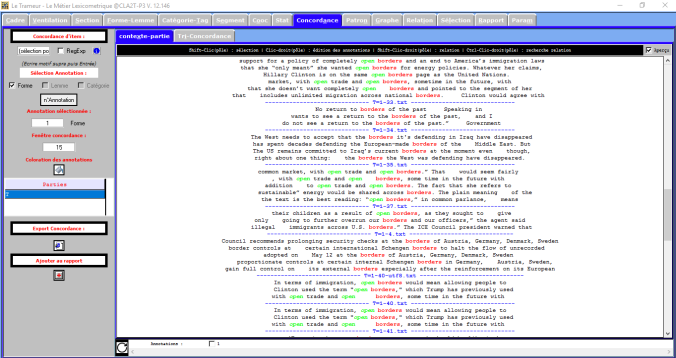
On remarque qu’en anglais le mot « fermer » n’apparaît pas avec la même fréquence qu’en italien et en français. Au contraire, c’est le mot open qu’ apparaît le plus souvent. Pour connaitre la raison de cette différence on va analyser le mot « open » dans son contexte. On se rende compte que ce mot est utilisé pour indiquer des frontières commerciales, dés qu’en anglais et en italien il est utilisé pour indiquer la fermeture des frontières pour contenir l’immigration.
Voilà la nuage de mots sur le fichier DUMP-TEXT:

Et celle sur le CONTEXTE:

