UN PEU DE THEORIE…
Dans cette partie de notre blog, on expliquera brièvement comment on devra travailler pour la mise en œuvre de notre projet et quelles sont les commandes pour le faire apprises pendant le cours.
Le but est de créer un fichier de sortie HTML, avec un tableau où écrire des informations concernant nos URLs, comme le numéro du lien, la page aspirée, l’encodage, etc. Tout doit être codé en UTF-8 (un codage de caractères informatiques).
Pour arriver à ce résultat on partira de notre fichier contenant les URLs .
- La récupération des URLs sera effectuée avec wget ou curl, qui nous permettront d’aspirer les pages web et numéroter les liens.
wget : permet le téléchargement d’un fichier depuis le web.
- wget [options] [url] : permet l’enregistrement du fichier dans le dossier courant.
- wget -i : lit les adresses depuis un fichier.txt.
- wget -k : convertit les liens pour être disponible en consultation locale.
- wget -p : télécharge tous les fichiers requis pour une consultation convenable d’une page HTML.
curl : un outil de commande qui permet de télécharger et envoyer des données sur différents protocoles.
- curl [options] [url] : télécharge un fichier ou une page web et affiche son contenu dans la console.
- curl -s : utilisé pour détecter l’encodage de la page web.
- curl -C : reprend un téléchargement que l’on avait arreté.
- Une fois les pages aspirées et stockées localement, on utilise la commande lynx pour la récupération du texte brut.
lynx : un navigateur web en mode texte utilisable via une console ou un terminal.
- lynx [options] [url] : ouvre une page web dans la console.
- lynx -dump : sortie formatée avec liste numérotée des liens.
- lynx -source : donne le fichier source, non formaté.
- Après la récupération du texte brut, il faut changer l’encodage des données associés aux URLs en UTF-8 en utilisant les commandes file/egrep et iconv.
file : permet de déterminer le type d’un fichier.
- file -i : donne des informations sur le fichier, comme par exemple son encodage.
egrep : commande qui utilise les expressions régulières pour chercher un motif (par exemple un mot) dans un fichier.
- egrep -i « mot » : pour trouver tous les mots présentent dans le fichier.
- egrep -in « mot » : pour trouver les numéros des lignes où « mot » apparait.
- egrep -inv « mot » : affiche les lignes que ne contiennent pas « mot ».
iconv : commande qui permet de convertir un fichier d’un codage dans un autre.
- iconv -l : pour consulter la liste des encodages disponibles.
LA PRATIQUE!
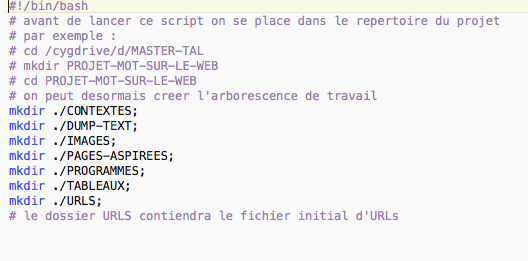
Tout d’abord, on prépare l’environnement du travail: les répertoires et les arborescences.
Avec de l’aide de la commande cd et mkdir, on peut facilement créer tous les fichiers dont on aura besoin dans le bon répertoire:


Pour bien présenter les étapes qu’on dois faires pour le projet, on a fait une graphe synthétiaue qui explicite clairement le déroulement du programme:
la graphe à faire
Maintenant on va aller chercher les urls sur le navigateur. Dès que les urls sont pretes, on les placera toutes dans un fichier text brut, il nous faut au moins 50 urls et il faut les placer dans le répertoire (dossier) qu’on a fait auparavant et qu’on l’a appelé URLS.
Ensuite, pour bien nous entraîner, on a suivi les étapes du premier pdf de cette séance: page officielle du projet.
Sur cette page, il y a déjà des solutions (scripts) proposées, mais quand je les lance directement sur mon ordinateur, ils me donnent des erreurs. Alors, je fais un peu des modifications pour que les scripts marchent avec mes urls sous mon ordinateur.
1) . Premier script: créer un tableau des liens

le résultat du premier script:

2). second script: liens externes et liens internes

créer un variable ( une autre colonne « pages aspirées ») dans le tableau:
le résultat du second script:

3). troisième script: créer un tableau de liens avec 3 colonnes ( URLS, PAGES ASPIRÉES et DUMP)

Le résultat du troisième script:

Enfin, je lance le grand script que le prof a montré pendant le cours et qu’il a bien expliqué, et on a eu le bon résultat:

bravo!
et on veut aussi mettre sur notre blog les scripts détaillés dans la page officielle du projet, il est très bien expliqué et très claire;

26/10/2016
